|
关于 PolarDB PostgreSQL 版 PolarDB PostgreSQL 版是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 、Ganos全空间数据处理能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL 版具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载。 PolarDB PostgreSQL高可用架构 传统计算与存储紧耦合的数据库系统架构面临诸多挑战,如: 1、存储空间无法超过单机上限,不易实现资源的快速扩容; 2、一台物理机的不同资源难以同时具有较高的利用率,资源易碎片化; 3、单一资源故障会导致系统整体故障,系统恢复时间长。 PolarDB PostgreSQL采用计算与存储分离的架构,相比于紧耦合架构,存储资源被单独解耦组成一个独立的存储池,可独立提高存储池的资源利用率;同时主节点与多个只读节点可共享同一份存储,节约了只读节点的存储开销,进一步降低了存储成本;计算存储分离的设计使得计算集群与存储集群均可独立扩展,极大地提高了资源弹性;此外节点间通过日志信息来同步内存状态,不会产生IO,大大降低节点同步延迟,为极致高可用提供了基础。 在计算存储分离的架构下,PolarDB PostgreSQL可同时提供AZ内/跨AZ/跨域级别的高可用。这里把一个PolarDB数据库计算与存储节点,以及高可用控制模块、运维管理模块,统称为一个PolarDB集群。从数据层面来看,PolarDB的高可用架构如下:
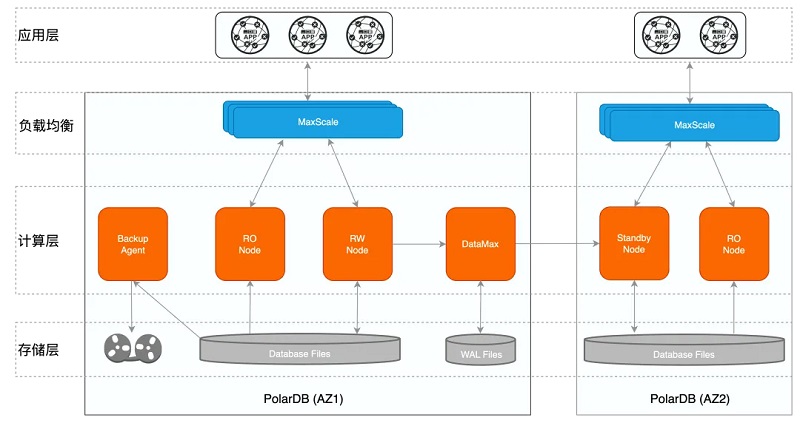
单套PolarDB集群部署在一个可用区内,不同的PolarDB集群之间互为灾备,主备模式保证跨AZ/跨域级别的高可用; 1、PolarDB集群为一写多读架构,读写节点共享同一份存储,有效降低存储成本,同时只读节点还可实现单个AZ内计算节点的高可用; 2、DataMax节点只保存WAL日志文件,不与写节点共享数据,在提供远程同步功能的同时,可以更高效地实现跨域级别的高可用; 3、BackupAgent通过调用分布式文件系统的接口进行快速数据备份,备份支持本地盘、OSS、DBS等,保证故障发生时可基于备份进行数据的恢复,防止数据丢失/损坏; 4、MaxScale是代理层,可自动识别读写请求,根据只读负载将读请求发送给不同的只读节点,通过读写分离实现负载均衡。 在一个可用区内,PolarDB的RW、RO节点间保持接近于实时的内存同步,如果RW出现故障,可以随时进行RW/RO节点切换,实现单个AZ内的高可用;在集群间,两个集群通过日志进行物理复制,中间有一个DataMax日志中继节点,主集群与DataMax间配置为同步模式,远程集群配置为异步复制,从而在性能稳定的情况下,保障跨AZ/跨域高可用的RPO=0。此外,如果用户有3个可用区,还可以部署为Paxos三节点模式,其中一个节点只保存日志,从而实现低成本超高可用性能力。 从控制层面来看,PolarDB的高可用架构如下:
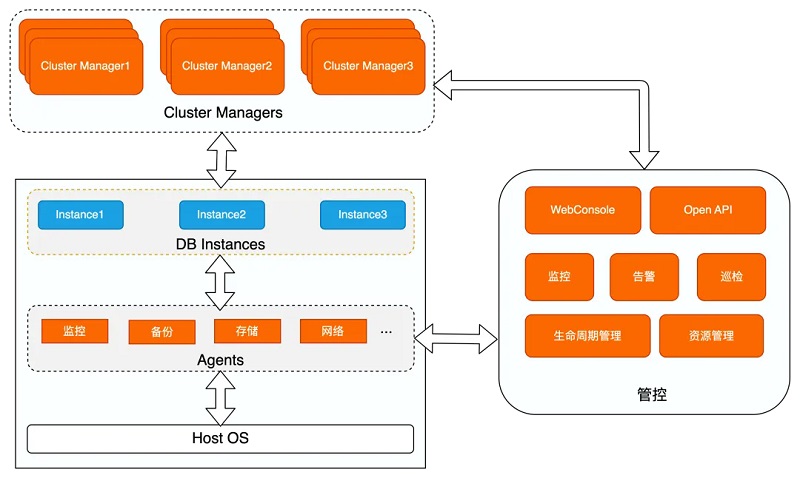
其中: 1、Cluster Manager为集群管理中心,通过心跳数据监控数据库实例、MaxScale及Agent的可用性,通过切换或重启异常节点来维护集群的高可用,提供主动监控和快速检测故障的能力; 2、运行在主机上的不同Agent负责监控、采集或配置数据库实例和主机的信息,并生成对应的监控视图,同时部分指标也输出至Cluster Manager中辅助决策; 3、管控负责资源管理及数据库实例生命周期管理,其基于Agent采集的信息进行监控及告警,便于更快速及时地响应并处理故障,同时提供web端供用户查询及修改,提供Open API接口给第三方平台调用,使得数据库的管理更加便捷。 PolarDB用户可以根据自己的实际情况和SLA要求,在单可用区、双可用区、三可用区、跨域等多种环境下,灵活的选择可用性方案。下面分别对单可用区内计算节点的高可用、双可用区/跨域间计算集群的高可用、三可用区DMA高可用方案的核心技术及原理进行详细介绍。 计算节点高可用 PolarDB单个AZ内计算节点的高可用通过只读节点RO实现,读写节点RW与只读节点RO共享底层存储数据,RW落盘的数据RO可直接读取。因此当读写节点RW异常crash时,可通过将RO节点提升为RW节点来实现计算节点的高可用。由于RW节点与RO节点共享存储,因此可保证RPO=0。为保证应用层服务所见数据的一致性,RO节点提升为RW节点之后,需回放完存储上的所有WAL日志数据才可对外提供服务,因此RO与RW之间的延迟对于RTO至关重要,而且越小越好。节点间是通过传输日志信息进行同步的。注意这里只传输日志的Metadata信息,这些日志非常容易解析,这样做可以让RO以接近于实时的延迟接收、解析这些Metadata。接收这些信息后,RO查找自己的Bufferpool,如果Bufferpool有对应的页面,则对这些页面进行失效操作。当RO上有查询读取到这些失效页面,则对这些失效页面单独查找和应用其对应的日志,使其重新变为有效的新版本页面。这种技术有如下优势: 1、流复制只传输WAL Metadata数据,降低网络传输量和解析时的CPU消耗; 2、日志同步时,只对内存页面做失效操作,无需读取和应用日志,不会有IO操作。 这样,RO用最少的数据量和步骤完成了同步,实现了极致的(通常低于1ms)的RO与RW节点延迟,确保了RO一致性和可用性。下面详细介绍这个同步过程。
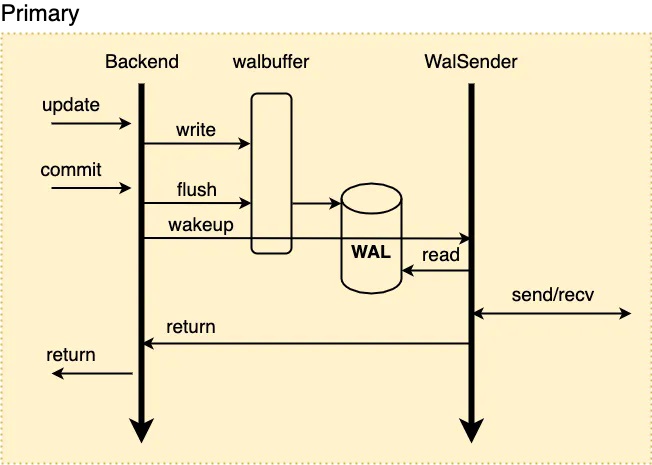
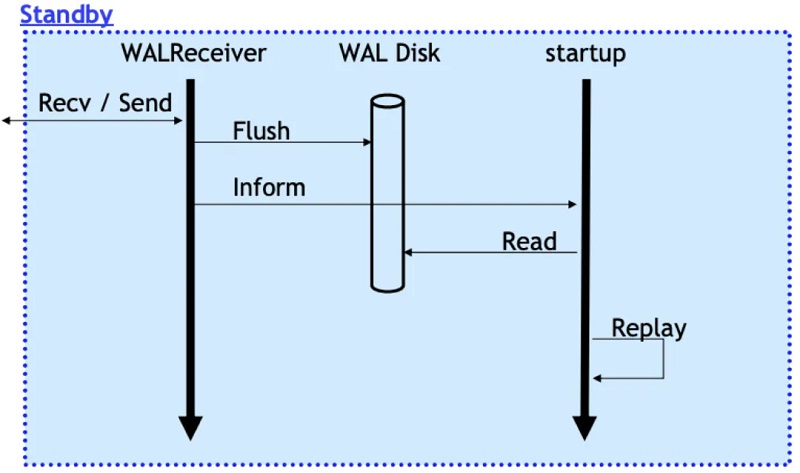
节点间同步原理 先看下传统主备模式下,流复制传输与备库回放日志的过程: 1、当RW节点中的事务对其数据进行修改时,会生成对应的WAL日志并将其写入walbuffer; 2、同步流复制模式下,事务提交时会先将walbuffer中对应的WAL日志flush到磁盘,此后会唤醒WalSender进程; 3、WalSender进程发现有新的日志可以发送,则从磁盘中读取对应的日志数据,通过已建立的流复制连接发送到对端的Standby; 4、Standby的WalReceiver进程接收到新的日志数据之后,同样地将其flush到对应的磁盘日志文件中,同时通知Startup进程有新的日志到达; 5、Startup从磁盘文件中读取对应的XLOG Record进行回放。
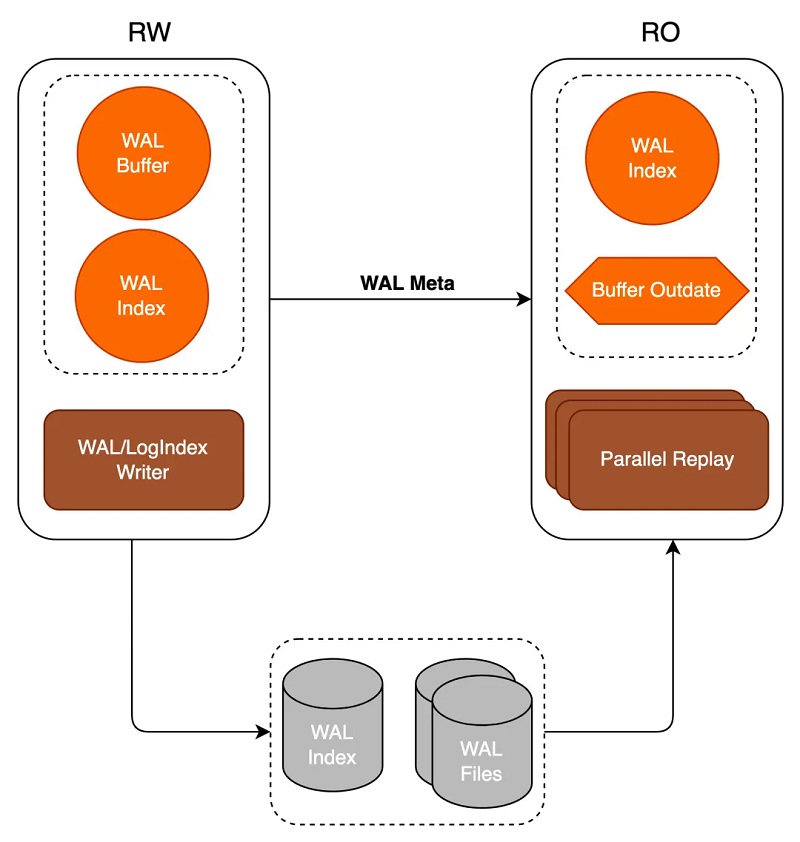
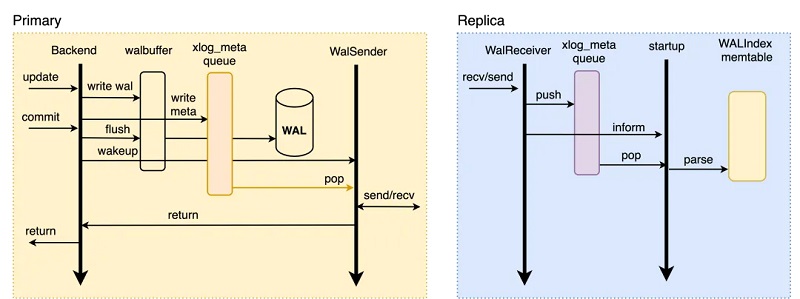
在PolarDB这种共享存储模式下,RW与RO共享底层存储数据,因此RW无需传输WAL日志的全部内容至RO,只需传输WAL日志元信息META,RO可基于META直接从底层存储上读取所需要的WAL日志数据,如下所示: 1、当RW节点中的事务对其数据进行修改时,会生成对应的WAL日志并将其写入walbuffer,同时拷贝对应的WAL meta数据至内存中的meta queue中; 2、同步流复制模式下,事务提交时会先将walbuffer中对应的WAL日志flush到磁盘,此后会唤醒WalSender进程; 3、WalSender进程发现有新的日志可以发送,则从meta queue中读取对应的WAL meta,通过已建立的流复制连接发送到对端的RO; 4、RO的WalReceiver进程接收到新的日志数据之后,将其push到内存的meta queue中,同时通知Startup进程有新的日志到达; 5、Startup从meta queue中读取对应的meta数据,解析生成对应的WAL Index memtable即可。
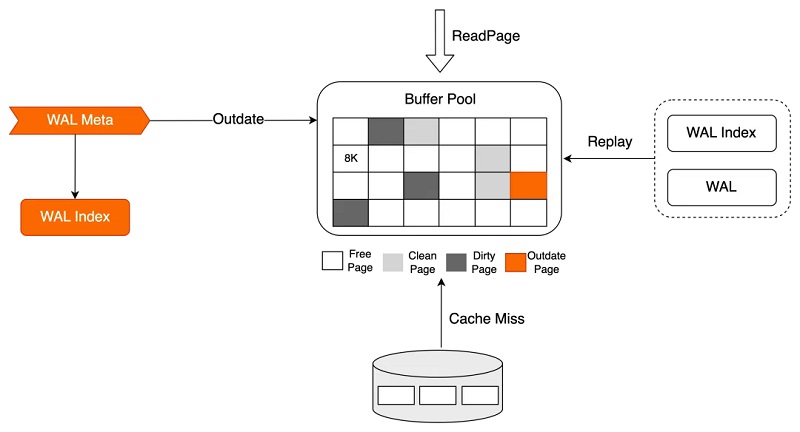
RO的Startup并不实质读取WAL日志并进行数据回放操作,数据的回放被延后到真正有用户进程访问该page时进行: 1、Startup回放进程在接收到WAL meta数据后仅在内存中生成对应的WAL Index,同时若该WAL meta对应的page存在于Buffer Pool中,则将其标记为Outdate; 2、会话进程进行数据访问时,若该对应的page不在Buffer Pool中,或在Buffer Pool中被标记为Outdate,则基于WAL Index检索属于该页面的需要回放的WAL日志,并从磁盘上读取对应的WAL日志数据进行真正的回放操作,回放完成后向会话进程返回对应数据。
通过减少流复制过程中读取/接收WAL引入的磁盘IO操作,同时减少网络传输量,以及将真正的回放过程转移到会话进程中等优化,加速了RO节点的内存同步进程,将RW与RO之间的延迟降至了最低(通常1ms以内),从而提升了RO的可用性。 Online Promote 在共享存储架构下,最简单的节点切换方式,是基于重启的方式进行HA切换。在这种方式中,RW异常crash之后,RO节点以RW身份重启,此时新的RW需要从checkpoint点开始回放完所有日志之后才可对外提供服务,当checkpoint落后较多时,新的RW启动过程中需要回放较多的日志数据,导致异常crash后服务恢复时间长。 为了避免重启方式的问题,PolarDB使用Online Promote的方式将RO提升为RW,该过程无需重启RO节点:

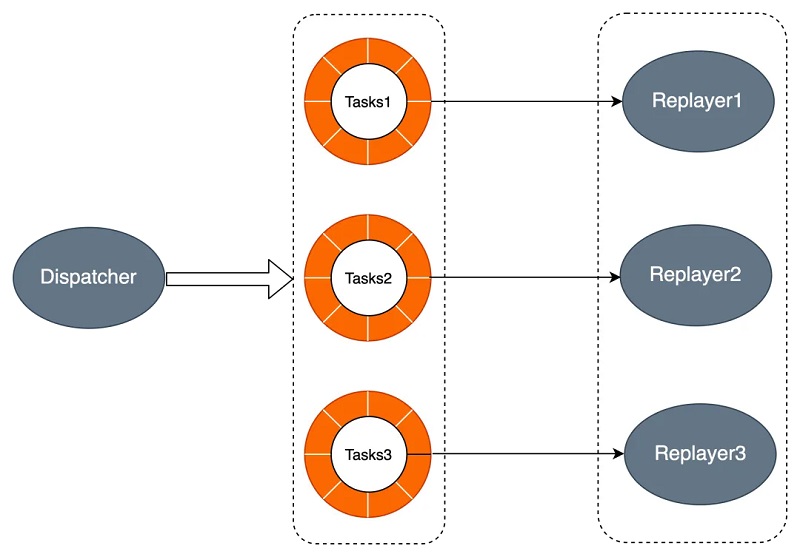
在Online Promote过程中,Promote后RO从切换前的Replay回放位点继续回放老的RW生成的日志。同样的,RO节点的回放过程仅生成对应的WAL Index数据,WAL Index生成完毕之后即可恢复服务,会话进程访问Page时,基于WAL Index回放该Page对应的WAL日志,RO需要回放的日志数量并不受checkpoint影响,通过Online Promote减少RO需要回放的日志量,缩短回放时间,从而加快服务恢复的速度。 并行回放 除了上述两点,PolarDB同时通过并行回放加速HA时RO的回放速度,原理如下所示。Dispatcher进程将回放任务推送到各个进程的任务队列,进程组中进程读取各自任务队列中的任务进行回放。
PolarDB通过优化RO节点的内存同步过程,极大地降低了RW与RO之间的延迟,同时通过Online Promote和并行回放加速了HA时服务的恢复速度,可在保障RPO为0的同时,以较低的RTO实现单个可用区内的高可用。此外,PolarDB基于Cluster Manager,还可实现对集群状态的主动监控及对故障的快速检测,提供自动化的故障处理恢复能力,保证服务的连续可用性,下面详细介绍Cluster Manager的实现。 Cluster Manager Cluster Manager负责集群及配置管理,自动化的维护集群的高可用,其内部模块如下: 1、Detector探测模块通过心跳请求探测数据库的可用性,默认为3s超时,当发生超时时,同时会有一个backup心跳进行辅助决策,避免特殊情况导致误判,backup心跳默认超时为60s; 3、Collector采集模块获取各个维度的实时监控信息,包括操作系统、容器、存储及数据库内核的多个指标,结合所有指标即可得到当前数据库实例的运行状态,用于分析及决策; 4、Decision决策模块基于上述获取的实例运行状态进行决策,如对数据库实例节点及MaxScale节点的可用性进行决策,对实例及其状态变更进行决策; 5、Action执行模块实施Decision决策模块下发的决策,如重启数据库节点,进行HA切换,对实例进行只读锁定等; 6、Plugin插件模块获取Manager提供的集群节点拓扑信息及负载情况,便于其对自身的行为进行调整。
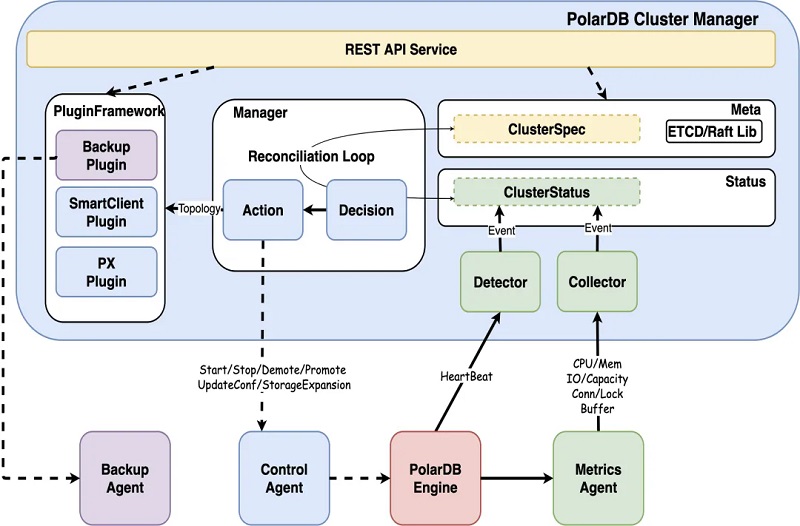
部分典型的异常故障场景如下,Cluster Manager会依据多维度的信息进行判断与决策: 异常场景 决策数据 计算节点宕机 多维度超时、容器主机数据避免误判 计算节点网络中断 多维度超时 计算节点网卡故障 多维度超时、网卡状态监控 计算节点存储挂载丢失 心跳超时、存储挂载状态监控 数据库内核Crash 心跳状态 数据库内核OOM 心跳状态、内存状态 数据库IO hang 心跳超时、等待事件、IO指标决策 计算节点丢包10% 心跳不持续性超时 计算节点网络延迟100ms 心跳不持续性超时 RO回放延迟 复制状态、buffer使用率 当探测到节点不可用时,Cluster Manager会进一步下发恢复策略: 1、若RO节点不可用,则对RO节点进行重建; 2、若RW节点不可用,则进一步判断RO节点状态,若RO节点可用,则触发HA切换,筛选符合要求的RO,将其提升为RW,并重建RO; 3、若RW与RO节点同时不可用,则先进行重启,若RW与RO节点持续不可用,则进一步判断Standby节点是否可用,若可用则触发切换,筛选符合要求的Standby,将其提升为RW,并重建Standby。 Cluster Manager实现了自动化的监控、切换决策、切换流程,在不需要用户干预的情况下,确保了RTO。Cluster Manager可对多个可用区的实例状态进行监控,实现AZ内/跨AZ/跨域级别的自动化故障检测及恢复,下面对跨可用区的计算集群间的高可用实现进行介绍。 计算集群高可用 DataMax节点 PolarDB通过增加RO只读节点实现单个AZ内计算节点的高可用,同时增加DataMax节点来更高效地实现计算集群的高可用。PolarDB基于物理流复制实现主库与备库之间的数据同步,主库与备库的流复制模式包含同步及异步两种: 1、异步模式下,主库的事务提交仅需等待对应日志写入本地磁盘文件中后,即可进行之后的提交操作,备库的状态对主库的性能无影响。但异步模式下无法保证RPO=0,备库相较主库存在一定的延迟,若主库所在的集群出现故障,此时切换至备库可能存在数据丢失; 2、同步模式包含不同的级别,可通过synchronous_commit参数进行设置,包括: 1)remote_write:该模式下,主库的事务提交需等待对应日志写入主库磁盘文件及备库的系统缓存中后,才能进行之后的事务提交操作; 2)on:该模式下,主库的事务提交需等待对应日志都已写入主库及备库的磁盘文件中后,才能进行之后的事务提交操作; 3)remote_apply:该模式下,主库的事务提交需等待对应日志写入主库及备库的磁盘文件中,同时备库已经回放完对应日志使其对备库上的查询可见后,才能进行之后的事务提交操作。 同步模式保证了主库的事务提交操作需等待备库接收到对应的日志数据之后才可执行,从而实现了主库与备库之间的零数据丢失,可保证RPO=0。但同时,该模式下主库的事务提交操作依赖备库的日志接收结果,因此若主备之间距离较远导致传输延迟较大时,同步模式会对主库的性能带来影响;极端情况下,若备库异常crash,则此时主库则会一直阻塞在等待备库的过程中,导致无**常提供服务。 针对传统主备模式下同步复制对主库性能影响较大的问题,PolarDB新增DataMax节点用于实现远程同步,如下:
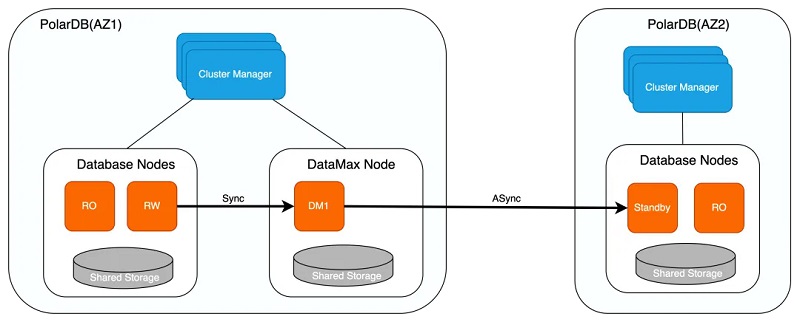
1、DataMax节点仅保存WAL日志文件,并不对日志进行回放操作,不保存RW节点的数据文件,降低存储成本; 2、DataMax节点与RW节点数据不共享,两者的存储设备彼此隔离,以防止计算集群存储异常导致的RW节点与DataMax节点保存的日志都丢失; 3、DataMax节点与RW节点之间为同步复制模式,确保RPO=0,DataMax部署在距离RW节点较近的区域,通常与RW节点位于同一可用区,以减小日志同步对主库带来的性能影响; 4、DataMax节点将其自身接收日志发送至其他可用区的Standby节点,Standby节点接收并回放DataMax节点的日志实现与RW节点的远程同步,Standby节点与DataMax节点之间可设置为异步流复制模式,通过DataMax节点可分流RW节点向多个备份数据库传输日志的开销。 集群高可用 如下,若RW节点与RO节点同时异常,或存储无法提供服务时,则可将位于不同可用区的Standby节点提升为RW节点,保证服务的可用性。在将Standby节点提升为RW节点并向外提供服务之前,会确认Standby节点是否已从DataMax节点拉取完毕所有日志,由于DataMax节点与RW节点为同步复制,因此可保证该场景下RPO=0。
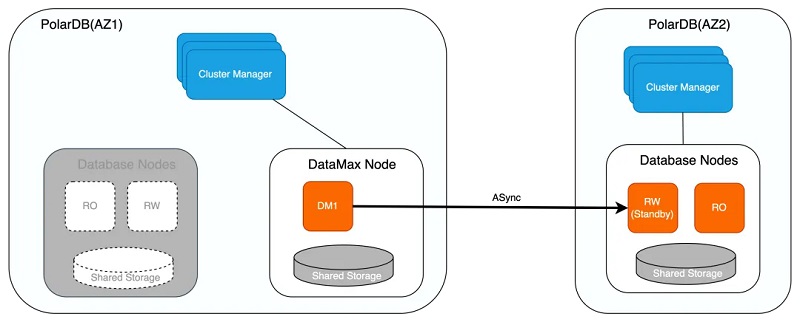
若DataMax节点异常,则优先尝试重启进行恢复,若重启失败则对其进行重建,因DataMax节点与RW节点存储彼此隔离,因此两者数据并不互相影响,此外DataMax节点可同样采取计算存储分离架构,确保DataMax节点的异常不会导致其存储的WAL日志数据丢失。
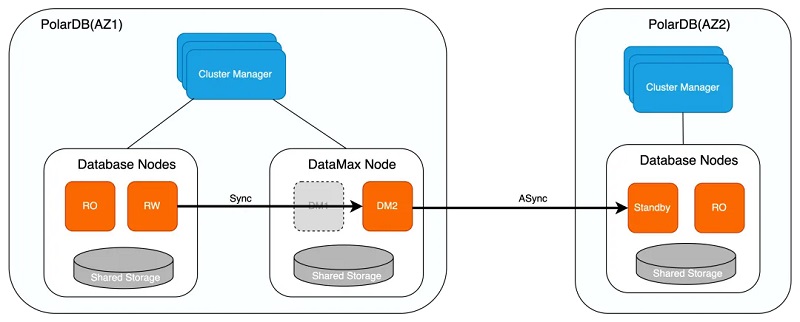
类似地,DataMax节点实现了如下几种日志同步模式,用户可以根据具体业务需求进行相应配置: 1、最大保护模式 1)该模式下,DataMax节点与RW节点进行日志强同步,确保RPO=0; 2)若DataMax节点因网络或硬件故障无法提供服务,RW节点也会因此阻塞而无法对外提供服务; 2、最大性能模式 1)该模式下,DataMax节点与RW节点进行日志异步流复制,DataMax节点不对RW节点性能带来影响,DataMax节点异常也不会影响RW节点的服务; 2)若RW节点下的存储或对应的集群发生故障,则可能导致丢失较多数据,无法确保RPO=0; 3、最大高可用模式 1)该模式下,当DataMax节点正常工作时,DataMax节点与RW节点进行日志强同步,即为最大保护模式; 2)若DataMax节点异常,则RW节点将同步模式降级为最大性能模式,保证RW节点服务的持续可用; 3)当DataMax节点恢复正常后,则RW节点再次将异步模式提升为最大保护模式,避免日志数据出现较多丢失。 通过DataMax日志中继节点降低日志同步延迟、分流RW节点的日志传输压力,可在性能稳定的情况下,保障跨AZ/跨域高可用的RPO=0。 DMA高可用 上述方式实现的集群高可用需通过日志强同步保证RPO=0,当出现网络抖动或备份节点故障时,都会对集群的可用性带来影响。此外,集群节点可用性的判断与高可用决策依赖Cluster Manager,数据库集群本身不具备自主高可用或自运维能力,针对此,PolarDB同时提供了基于DMA的高可用形态(即三节点形态),具体如下:
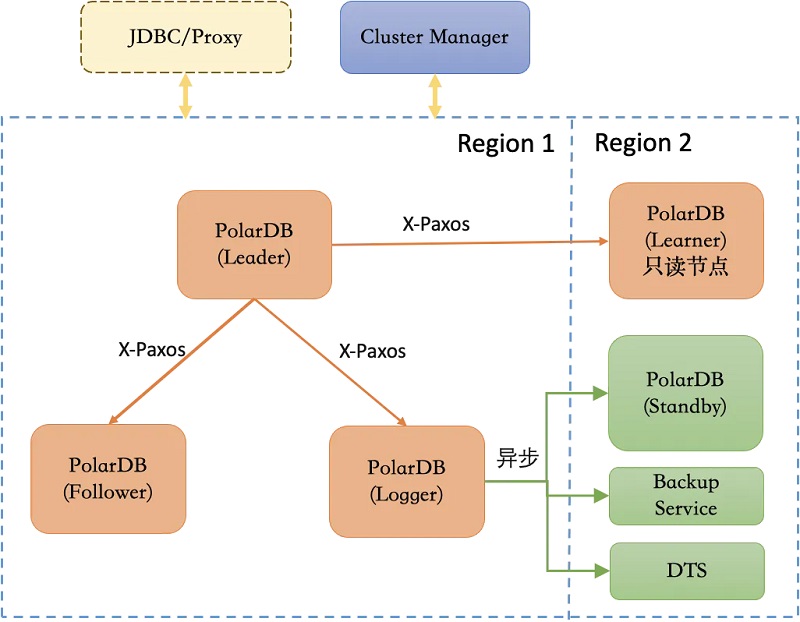
1、DMA在数据库内核中引入Raft分布式协议,基于X-Paxos进行日志同步,同时可对主备节点状态进行管理及协调,在发生故障时进行自主failover,具备自主运维及自主高可用能力; 2、DMA具备跨域高可用能力,可容忍N/2 - 1个节点故障,在少数节点故障时仍能保证RPO=0; 3、DMA可将X-Paxos与Cluster Manager相结合,保证故障发生后的RTO < 30s; 4、DMA对WAL日志流和Consensus日志流的传输链路进行了优化,可实现性能损耗相较于单机下降在10%以内; 5、DMA可同时接入DataMax作为其Logger节点,从而降低部署成本;此外该高可用架构还可保持与传统主备复制及原有工具如DTS的兼容。 Consensus与WAL双日志流 引入X-Paxos之后,DMA需通过Consensus日志复制来维护集群数据的一致性,同时主节点与备节点之间还需要WAL日志复制来实现数据同步,针对该问题,DMA采用了Consensus log与WAL log双日志流的方式:
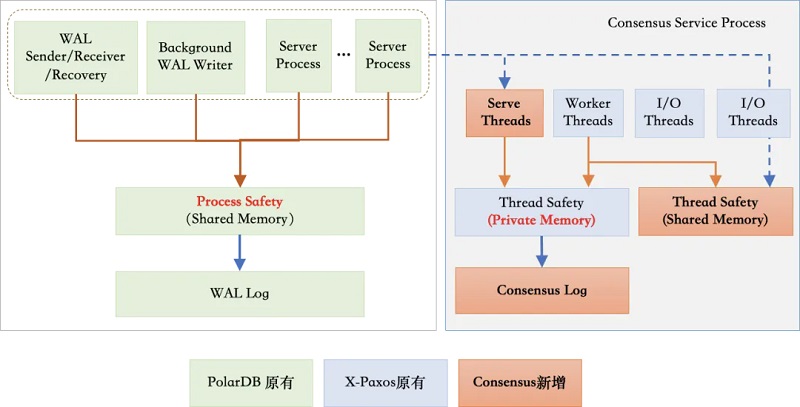
其中WAL日志复制采用原生方式,保持与社区的兼容性。Consensus日志与WAL日志独立,仅在Consensus日志中记录WAL日志位点,Consensus日志提交成功即代表相应位点之前的WAL日志也在多数派上提交成功。此外,DMA还对双日志流的传输进行了优化,加快了双日志流的传输速度,从而提升了整个集群的可用性,下面详细对此进行介绍。 日志传输链路优化 1、DMA中的日志传输流程如下: 2、Leader进行事务提交时,会生成对应的WAL日志并写入WAL buffer中; 3、Leader将Commit Record LSN之前的WAL日志刷盘,并唤醒WalSender进程将WAL日志传输至各个Follower节点 4、Leader的WalSender进程将WAL日志发送至Follower节点; 5、Follower节点的WalReceiver进程接收到WAL日志后写入本地WAL日志文件; 6、Leader通知Consensus服务进程WAL日志已落盘,并等待该LSN位点多数派持久化成功; 7、Leader传输WAL日志的同时,Consensus服务进程使用当前Flush LSN生成Consensus Entry,并通知X-Paxos多数派复制Entry; 8、Leader的X-Paxos调用Consensus Log/Consensus service接口本地持久化Entry内容; 9、Leader的X-Paxos向各个Follower发送Consensus Entry; 10、Follower的X-Paxos调用Consensus Log/Consensus service接口持久化Entry内容; 11、Follower的X-Paxos向Leader response本地持久化等信息; Leader的X-Paxos尝试更新commitIndex信息,推进后唤醒等待中的进程,完成事务提交操作。
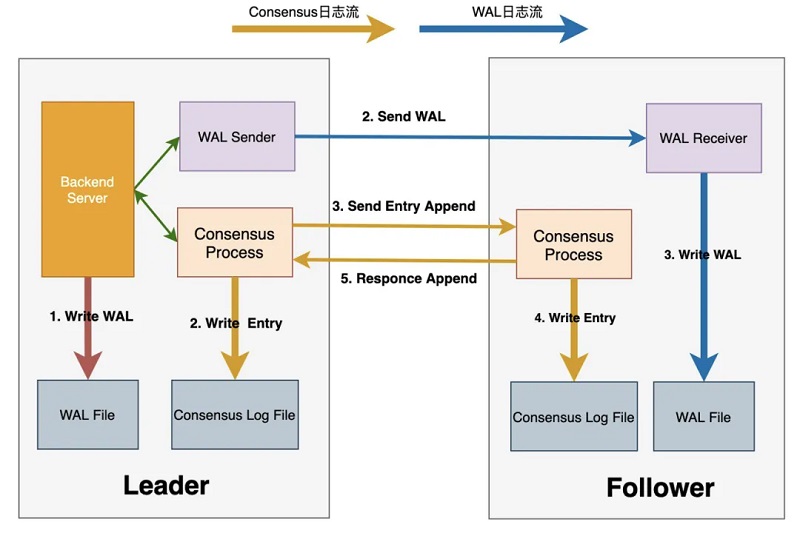
从上述流程可知,整个提交流程至少包含三次IO操作及两次网络交互,即上图中1~5的步骤,其中WAL日志传输与接收,同Consensus日志的生成与传输可同步进行,该提交流程对提交时延及IOPS均会带来一定的影响。针对此,DMA首先将持久化Consensus Entry的IO操作与WAL Flush操作进行了合并。如下,Leader节点在生成对应WAL日志时,同时依据当前Commit Record LSN生成对应Consensus Entry,放入Consensus Entry SLRU中,类似地,Follower节点确保相应的WAL日志已接收完成后,将Consensus Entry写入SLRU中。Leader节点及Follower节点持久化Entry的操作均可异步进行。
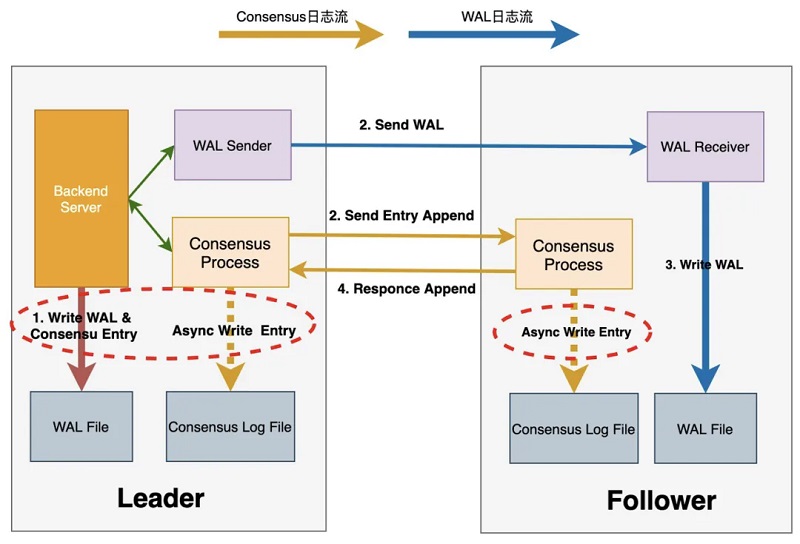
同时将Leader FLush WAL的操作与发送双日志流的操作并行化,两者结合之后,整个提交流程路径为: Max(1 I/O, (Max(1 RTT, 1 RTT +1 I/O) + 1 RTT)) = 1 I/O + 2 RTT,即仅包含一次IO操作和两次网络交互。在此基础上,还可将Follower节点的网络接收与WAL日志落盘并行化,从而进一步提升日志传输的性能。
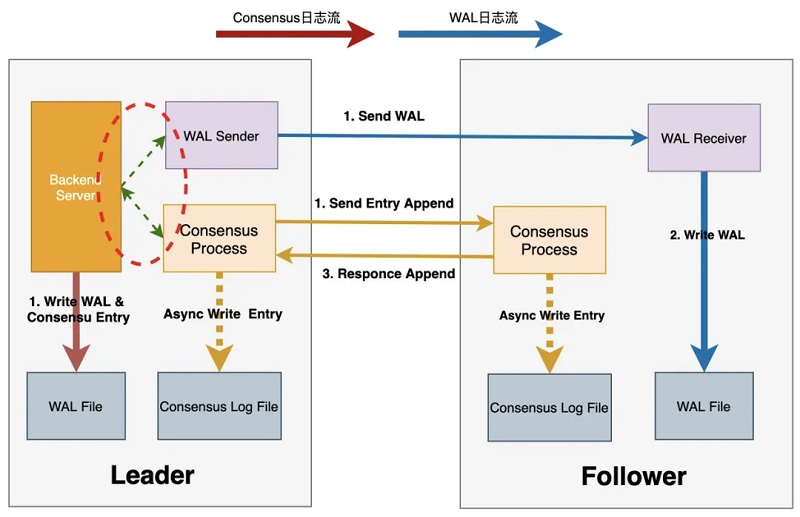
DMA三节点形态在保障RPO为0的同时,提升了对集群节点故障的容忍程度,使得集群自身具备了自主运维及自主高可用的能力,同时结合日志节点与日志传输优化,降低了高可用的实现成本与性能损耗。 总结 高可用是云原生数据库中不可或缺的一环,本文对PolarDB PostgreSQL版的高可用架构及几种典型的高可用实现方案进行了分析及介绍。PolarDB PostgreSQL通过RO/DataMax/DMA,可实现AZ内/跨AZ/跨域的高可用,并引入X-Paxos使内核具有故障感知及自主运维的能力,同时结合Cluster Manager根据多维状态配置策略进行故障探测和下发恢复决策,降低误判提升集群稳定性。此外,在保证RPO=0的同时,PolarDB PostgreSQL通过WAL Index、Online Promote、DMA日志传输链路优化等方式进一步提升从故障中恢复的速度,尽可能地保证服务最少中断或不中断。目前PolarDB PostgreSQL仍在持续探索及优化,以在保障RPO=0的基础上,以更低的成本、更快的速度、更全面的形态实现一体化、系统化的高可用解决方案。 来源:阿里云PolarDB
|  |手机版|小黑屋|CUUG认证培训
( 京ICP备11008061号 )
|手机版|小黑屋|CUUG认证培训
( 京ICP备11008061号 )




 发表于 2025-1-16 16:31:02
发表于 2025-1-16 16:31:02